本文作者给出了具有主观分数以及头部运动和眼部运动数据的全景视频 VQA 数据集。并且提出了基于深度学习并且整合了头部运动和眼部运动数据的全景视频 VQA 方法。
VQA-ODV
Database
reference
1
2
3
4
5video_num: 60 # 10 groups,6 per group
resolution: [4K, 8K] # a range, 3840 × 1920 pixels to 7680 × 3840 pixels
projection: 'ERP'
duration: [10, 23] # a range, unit: seconds
frame: [24, 30] # a range, unit: frames per seconds (fps)
impaired
1
2
3
4video_num: 540 # 3 compress * 3 projection * 60 references
compression_std: H.256
QP: [27, 37, 42] # quantization parameter, correspond to compress level
projection: ['ERP', 'RCMP', 'TSP']
Subjective data formats
数据集给出了 MOS 和 DMOS ,其中 MOS 的计算如下
其中 $S_{ij}$ 表示第 $i$ 个人对序列 $j$ 的评分,$I_j$ 表示第 $j$ 个序列的有效评分人数。
DMOS 计算参考论文 29
Content and formats
在一个序列上,一个用户的 HM 和 EM 表示如下
[Timestamp HM_pitch HM_yaw HM_roll EM_x EM_y EM_flag]
- Timestamp: 两个相邻采样点的时间间隔,单位毫秒
- HM data: 使用三个维度的欧拉角表示,pitch / yaw / roll
- EM data: 使用 x / y 表示 viewport 中的位置,x / y 属于
[0,1] - EM flag: 标记 RM 是否有效,1 为有效,0为无效。因为眨眼会使
EM无效,而HM则是一直有效的。
Analysis on VQA Results
主观质量 DMOS 分析
- 相同投影方式下,高比特率的视频序列具有更好的主观质量
- 相同比特率下,TSP 投影的主观质量比其他两类好
- 高比特率下,投影方式带来的主观质量差异不显著
客观分数 (PSNR/S-PSNR/SSIM) 分析其与对应序列的 DMOS 的拟合相关性 (SRCC/PCC/RMSE/MAE)
S-PSNR的相关性比传统的PSNR和SSIM指数要好
Analysis on Human Behavior
- 不同人的
HM权重图之间存在高的一致性 - 不同人的
EM权值图也存在高的一致性 - 所有人的 viewport region 相对于整个全景视频区域的比例小于 65%,即有感知冗余
Impact of Human Behavior on VQA
在计算有损序列的帧的 PSNR 时引入感知权重,即 HM/EM 数据。
考虑三类感知权重,overall HM (O-HM) / individual HM (I-HM) / individual EM (I-EM) 。记用户 $i$ 的 viewport 对应的像素集合为 $\mathbb{V}_i$
用户 $i$ 对一全景帧的 I-HM 权重图 $w_i^{I-HM}$
${\rm p}$ 表示像素。
每个全景帧的 O-HM ,为加权每个用户的 I-HM
$\mathbb{P}$ 表示全景帧的所有像素。
I-EM 权重图 $w_i^{I-EM}$ 是高斯形式
${\rm e}_i$ 是用户 $i$ 的 EM 位置,${\rm e_p}$ 是 viewport 中像素 ${\rm p}$ 的位置。
然后对失真序列和参考序列之间的误差加权,计算 ${\rm PSNR_{I-HM} }$ / ${\rm PSNR_{O-HM} }$ / ${\rm PSNR_{I-EM} }$
在计算以上 ${\rm PSNR}$ 和 DMOS 之间的相关度,得出 HM 和 EM 能提高客观质量分数的结论。
Deep Learning Base VQA Model
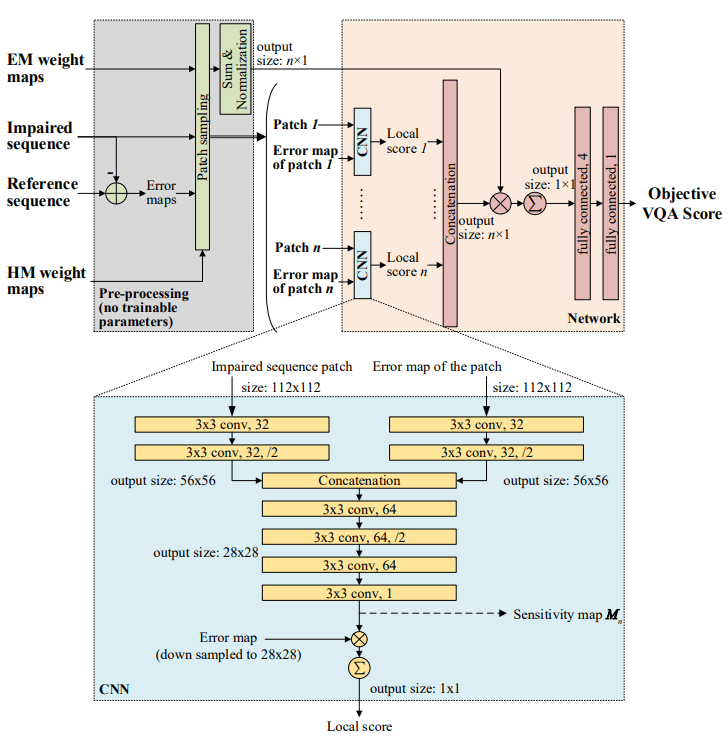
输入失真序列和参考序列。
预处理过程,计算失真序列和参考序列的误差,对给定 patch 对应的 HM 和 EM 权值分别求和作为 path 的权值,然后对每个全景序列采样 n 个失真 patches (size: 112 x 112),采样的概率是 patches 的 HM 权值。同样计算 n 个失真 patches 的误差图。
接下来将失真 patch 和对应的误差图输入一个计算二维图像的 VQA 的卷积神经网络组件( DeepQA 组件) 13 ,得到 n 个局部 VQA 分数。将 n 个局部分数拼接成 $n\times 1$ 的向量。同时将 n 个失真 patches 的权重除这些权值和得到一个 n 维的权重向量。最后接两个全连接层输出 Objective VQA score。
损失函数含有三项
其中 ${\rm s}$ 和 ${\rm s_g}$ 分别为预测客观 VQA 分数向量和 ground truth DMOS 分数。${\rm M}_k$ 是 $k$-th CNN 组件输出的 sensitivity map。${\rm Sobel}_h$ 和 ${\rm Sobel}_v$ 分别是在像素坐标系中水平和垂直的 ${\rm Sobel}$ 操作。$\beta$ 是网络的所有训练参数,$\lambda_i$ 是权值。
- Mean square error: 测量客观分数和主观分数之间的欧式距离
- Total variation regularization: 惩罚高频分量内容,因为人眼对高频分量不敏感
- ${\rm L}_2$ regularization: 防止过拟合
Evaluation
随机取 12 个参考序列及其 108 个失真序列作为测试集,其余 48 个参考序列和 432 个失真序列作为训练集。并且将序列进行空间下采样到 960 像素,时间下采样到 45 帧。并且使用预测的 HM 图和 EM 图。
对比对象:DeepQA 、S-PSNR 、CPP-PSNR 、WS-PNSR (第一属于深度学习方法)
对比方式:客观分数与主观分数之间的相关度( PCC 、SRCC 、RMSE 和 MAE )
结果:使用预测 HM 图和 EM 图时,本文方法显著优于其他方法。
消融实验:使用 group truth HM 图和 EM 图,本文方法有进一步提升,表示 HM 图和 EM 图的精度会影响本文方法。
Problem
What is the high frequency detail ?
Total variation (TV) regularization. It is applied to penalize the high frequency content as an smoothing constraint, since human eyes are insensitive to high frequency detail
which has the subjective scores of 600 omnidirectional sequencesWhat is the EM prediction in the model ? How to calculate it ?
This indicates that the accuracy of HM and EM prediction influences the performance of our VQA approach.
Annotation
13. Deep Learning of Human Visual Sensitivity in Image Quality Assessment Framework - IEEE Conference Publication ↩
29. Study of Subjective and Objective Quality Assessment of Video - IEEE Journals & Magazine ↩