该文是作者在 Generative Image Inpainting with Contextual Attention 后的又一个图像修复作品,在原来基础上,提出了 Gate Convolution 和 SN-PatchGAN 。
论文: Free-Form Image Inpainting with Gated Convolution
projection: Free-Form Image Inpainting with Gated Convolution · Jiahui Yu
Gate Convolution
vanilla convolutions
即普通卷积方式
上式忽略 bias 。所有的位置 $(x,y)$ 上都进行了相同的卷积。随着卷积窗口滑动,输入中 mask 覆盖的无效区域像素(以及模型深层中的合成像素)也被视为有效像素进行了卷积。
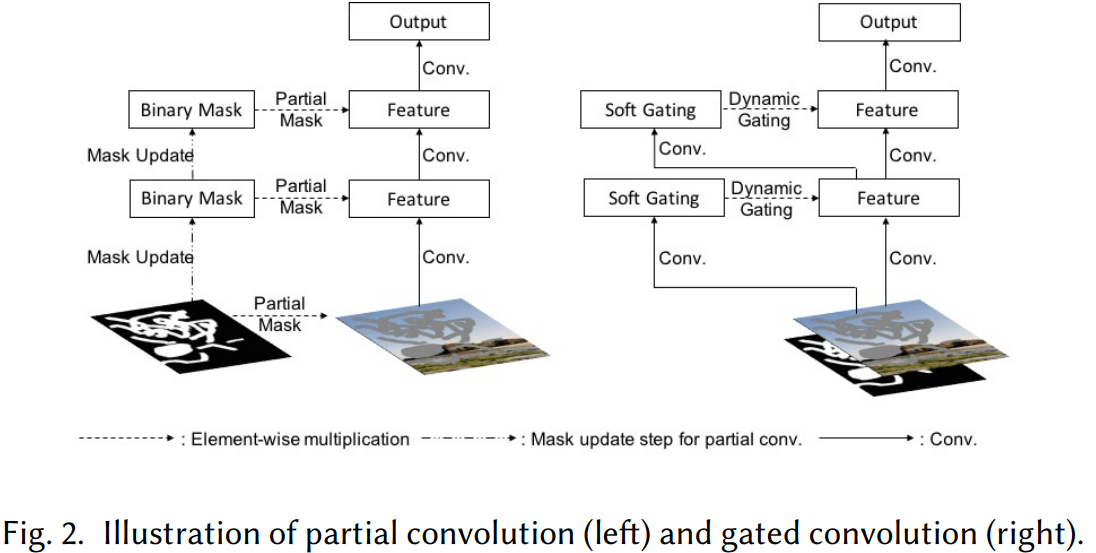
partial convolution
使用 mask 和 重归一化 进行卷积。mask 会随着卷积进行更新。卷积公式如下
其中 $M$ 为二值掩码 (卷积核大小区域),1 表示有效,0 表示无效。
若卷积区域内掩码全是无效的,则为0;否则进行卷积时先图像和掩码点乘消除无效区域,再进行卷积。
mask 的随着卷积的更新公式
- 由该更新公式可见,多次更新后,
mask将变为全 1,即全有效。 - 该
mask是可视为一个 hard 权重,即只有 {0, 1} ,无法引入用户导向的权证 - 所有通道共享同一个
mask
gate convolution
不使用固定规则来更新 mask ,而是学习一个 soft mask
其中 $W_g$ 和 $W_f$ 表示两个不同的卷积,分别用于更新 feature 和 gating ;$\sigma$ 为 sigmoid 函数,将 Gating 变换到 $[0,1]$ 用于作为权重;$\phi$ 为任意激活函数。
该方式可以为每个位置和每个通道学习到不同的权值,可视为动态 feature 选择机制。
在可视化 Gating 可看到,Gating 不仅选择了 背景、 mask 、sketches ,而且在深层中还有语义分割的权值选择。
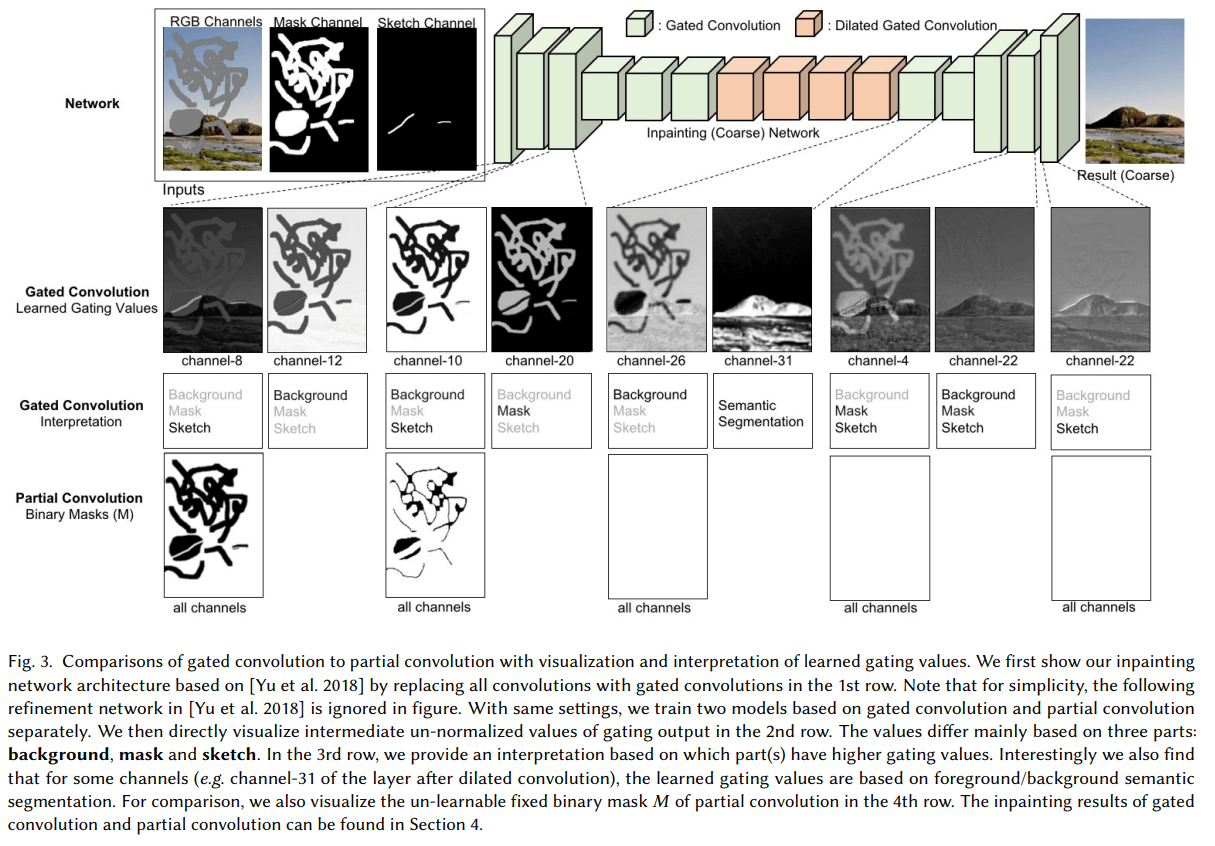
第二行是 Gating 的可视化,Gating 取值范围 [0,1] 可视化为灰度图,趋向白色的区域 Gating 取值趋向 1 ,表示大权重,即动态选择了白色区域的 feature 。第二行第六列,可以看出,Gating 白色区域是山,即学习到了具有语义内容的权重图。
第四行是 partial convolution 的可视化,可以看到,后面几层全是白的,即已经失去了对 feature 赋权的效果(权值均为 1 )。
SN-PatchGAN
Motivated by global and local GANs 、 MarkovianGANs 、perceptual loss 和 spectral normalized GANs
discriminator
使用一个卷积网络作为判别器,输入 image 、mask 和 guidance 通道,输出 3-D feature,形状 ${\mathbb R}^{h\times w\times c}$

判别器结构:六个卷积,kernel_size 5 ,stride 2 , 用于提取 Markovian 块的特征统计。然后直接在该 features 上使用 GANs 。通过参数设置, output map 中的每个 point 的接收域可以覆盖这个输入图像,所以不需要 global discriminator 。
采用 spectral normalization 的权值归一化技术进一步提升 GAN 的稳定性,使用 hinge loss 作为 objective function 如下
其中 $D^{sn}$ 表示 spectral-normalized 判别器,$G$ 为生成网络,$z$ 为 incomplete 图像。
最后生成网络的 objective function 由 $l_1$ 重构 loss 和 SN-PatchGAN loss 按 1:1 组成。
Inpainting Network Architecture
使用 Generative Image Inpainting with Contextual Attention 的构架,含有粗修复和细化两个阶段的模型。
粗网络使用 encoder-decoder 结构而不是 U-Net ,因为在 mask 的无效特征区域使得跳跃结构没有作用。
将网络中所有的普通卷积改为 Gate Convolution,由于参数变多,将模型 slim 25% ,同时发现这程度的 slim 不会让模型表现变差。
Free-Form Masks Generation
使用直线、旋转角度、圆来模型用户输入的 mask ,需要四个参数 maxVertex 、maxLength 、maxWidth 和 maxAngle ,分别表示顶点的最大数、直线的最大长度、直线的最大宽度、最大旋转角度 。另外,可以合成多个 mask (一个 mask 表示一个连续区域)表示多个区域的 mask。伪码如下

Extension to User-Guided Image Inpainting
对于面部数据,抽取 landmarks 并且连接相关的 landmarks 作为 sketches 。依据
- 用户感兴趣的地方大部分可能是面部的
landmarks - 检测脸部
landmarks的算法比检测edge的健壮
对于自然景观数据,使用 HED edge detector 抽取边图作为,将大于 0.6 的值改为 1 得到 sketches 。

作者发现,直接将 sketches 通道引入重构 loss 和 GAN loss 的计算中,就能够达到足够好的 user-guided 效果,而不需要额外添加 loss 。
Annotation
- Spectral Normalization
- WGAN 需要 Lipschitz 范数约束判别器
- Spectral Normailization 可以让判别器满足 Lipschitz 约束
- 只需让每层网络的网络参数除以该层参数矩阵的谱范数即可满足Lipschitz=1的约束,由此诞生了谱归一化(Spectral Normailization)。
Spectral Norm Regularization
「整个神经网络的扰动指数的上限」 是「各层子网络谱范数的乘积」。谱范数正则即惩罚函数的扰动指数
谱范数正则(Spectral Norm Regularization)的理解 - StreamRock的专栏 - CSDN博客
Markovian discriminator
texture/style是「高频分量」,Markovian discriminator (PatchGAN) 约束 $n\times x$ 大小的 Patch 上的高频分量
L1_loss 是逐像素计算,图像的颜色属于低频分量