本文提出一种联合压缩视频特征和视频内容的压缩方式。
- 对于特征编码,提出视频帧的块分区结构作为特征选择的有效参考
- 提出了多预测模型,利用运动和纹理信息提高 特征预测的效率
- 提出 RAO 实现比特率和检索表现的均衡
- 使用特征描述符改善帧间运动估计精度,提高视频压缩率
分别对应下文 Framework 的四点。
Framework
将视频序列视为连续帧的序列 $\{I^1,I^2,\cdots,I^i\}$ ,从 $I^i$ 帧上抽取的局部特征记为 $F^i$ ,其中 $f^i_j=(x^i_j,y^i_j,v^i_j) \in F^i$ 表示 $i^{th}$ 帧的第 $j^{th}$ 个局部特征,$x^i_j,y^i_j$ 为对应坐标,$v^i_j$ 为特征描述符向量。重构帧和其特征向量使用 $\widetilde I^i$ 和 $v^i_j$ 表示 。
本框架目标在于联合压缩 $I^i$ 和 $F^i$ ,最小化比特率且保证视频质量和特征检索能力 (feature retrieval ability)。整体分为两个部分,特征编码和视频编码
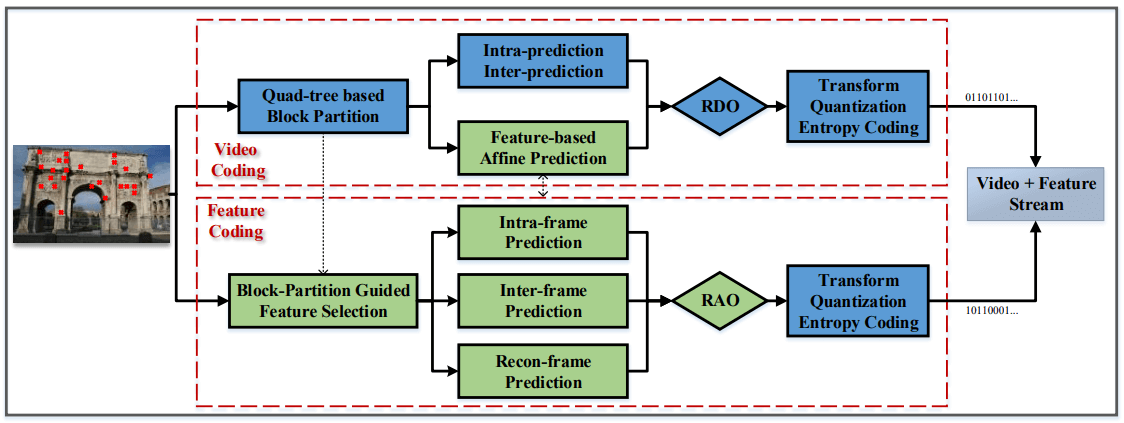
视频编码的四叉树结构可以用于指导特征选择,视频编码中的运动向量可以用促进特征预测操作的搜索过程。视频编码采用 HEVC 框架。
本框架适用于多种局部特征,本文以 SIFT 特征为例。
Block-Partition Guided Feature Selection
特征选取在于从感兴趣对象中抽取最相关的关键点,以增强视频检索的准确度,同时减少计算复杂度。
本文采用基于概率统计的特征选择方法 34 。使用 KRF 函数为每个特征分配一个正的意义值,表示该特征作为有效匹配特征的概率,并且估计其在检索任务中的主要程度。
基于 HEVC 的 CTUs 划分结构,本文提出使用分块结构指导特征选取,将 CU 划分深度作为 KRF 函数的一个属性,另外还引入了预测模式 (帧内或帧间预测) 和量化参数 (QP) 作为函数属性。
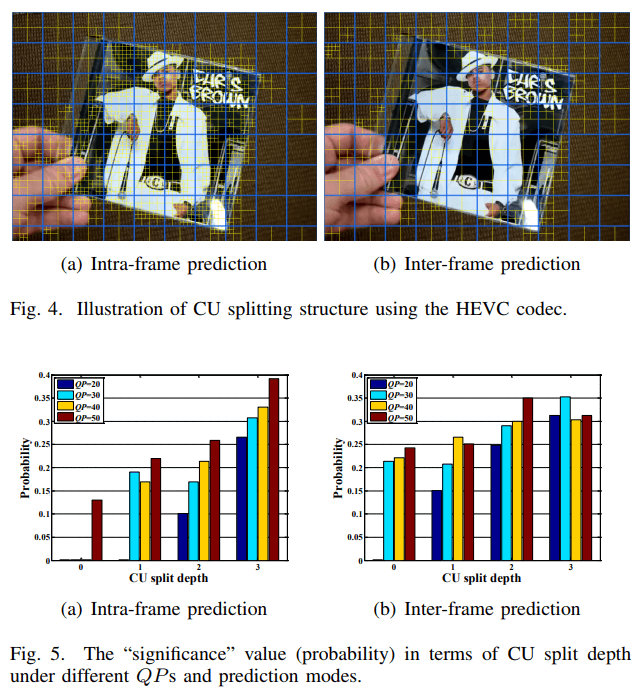
在不同 QP 和预测模式下训练,使用公共视频检索数据集 24 。通过进行视觉搜索匹配目标图像,对每个帧记录其重要特征及其CU深度。
其结果特点是,CU 深度越大、越可能检测到有意义的特征,尤其是在帧内预测中。
最后将结果的概率分布应用于 KRF 函数,计算每个特征的意义值,选取意义值最大的特征作为关键特征,用于压缩和检索,丢弃其他特征。
Multiple Prediction Modes
包含 intra-frame prediction、inter-frame prediction 和 reconstructed-frame prediction
intra-prediction 在于减少帧内冗余,利用图像的全局相似度
通过搜寻 最优的引用 $\widetilde v_{intra}$ ,来最小化如下代价函数
其中 $||v_j^i - \widetilde v_j^i||_1$ 为预测误差,$R(j-k)$ 为编码率,$\lambda$ 为控制二者关系的 拉格朗日乘子。
inter-prediction 在于减少帧间的时间冗余
通过复用视频运动信息,加速对参考帧的搜索。参考帧是指非压缩的原始帧。
在参考帧上进行运动评估,获得帧间预测块的运动向量,运动向量 $\rm MV$ 包含 运动偏移量 $(d_x , d_y)$ 和 参考帧索引 $d_i$ 。
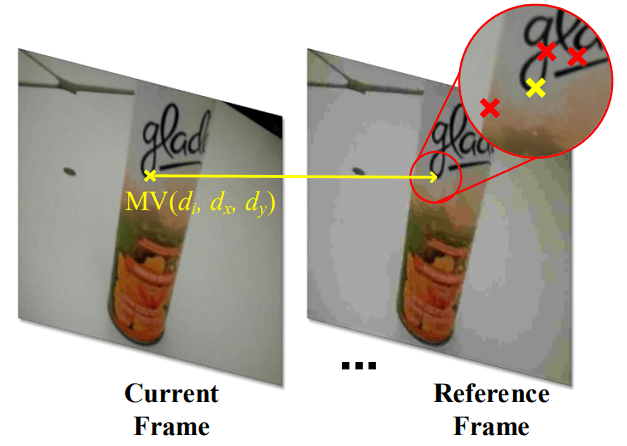
example: 从视频流中计算得到 $\rm MV$ ,对当前帧中的特征编码 $S^i_j = (x^i_j, y^i_j, v^i_j)$ ,在第 $(i-d_i)^{th}$ 帧中设置搜素原点为 $(x^i_j+d_x,y^i_j+d_y)$ ,搜索集合为 $\Psi$ , $\Psi$ 为与搜索远点最近的 $K_\Psi$ 个点 。搜索得到最优的帧间相关描述符 $\widetilde v_{inter}$
$K_\Psi$ 足够大时,其与暴力搜索相同,该参数调节了搜索复杂度和预测精度。本文设置 $K_\Psi$ 为 2 以平衡二者。
recon-prediction,其利用重构帧抽取的描述符作为参考,需要提取重构帧上进行完整的特征搜索,复杂度很大。本文提出使用 octave、scale 和 orientation 参数跳过关键检测过程。得到这些参数后,解码器可以直接提取出参考描述符。
而这三个参数中 orientation $\theta$ 为浮点数,需要在熵编码前量化为整数。问题转化为量化 $\theta$ 以达到有效的表达。记 $\theta$ 的量化表达为 $N_\theta$ ,最优量化表达 $\widetilde N_\theta$ 可以如下优化得到
其中 $D$ 和 $R$ 分别为预测错误函数和编码率函数,
其中$R(N_\theta) = \log_2(N_\theta)$ ,因为假设 $N_\theta$ 为固定整数长度;$D(N_\theta)$ 通过训练数据拟合 $D(N_\theta)=aN^b_\theta+c$ 函数得到。通过令导数为 0 ,得到最优化 $\widetilde N_\theta$
得到这三个参数后,即可有效的进行 recon-frame prediction
最后使用 RAO 从上述三种方法中选择最佳预测模式。为了最大化特征传输,需要对分块上的特征按梯度排序,再使用 2D-DCT 变换进一步减少数据冗余,然后使用 CABAC 算法进行熵编码。
Rate-Accuracy Optimization
Rate-distortion optimization (RDO):在约束的比特率下最小化失真,表达为非约束方式
$\lambda$ 为拉格朗日乘子,其控制 失真 $D$ 和 $R$ 比特率之间的关系
rate-accuracy optimization (RAO): 优化在约束比特率下特征描述符对检索任务准确度的影响
$D_A$ 为压缩描述符对视觉检索的表现下降程度,$R$ 为特征符号的比特率。
$D_A$ 通过排序原始特征与压缩特性的差异来评估表示。令 $v$ 和 $\widetilde v$ 表示原始特征和重构特征,$S$ 作为匹配目标的特征集合。对 $S$ 中的所有特征描述符 $d^i$ ,得到以一个升序列 $R_o$ ,其元素表示与原始特征 $v$ 的距离,其中 $K$ 为特征个数
类似的,$S$ 比较 重构特征 得到升序列 $R_r$
最后 $D_A$ 通过计算上面二个升序列的一致性得到,一致性由 SROCC 指数表示
实现时,集合 $S$ 表示前一帧的重构特征。
优化拉格朗日乘子 $\lambda$ 和 $\lambda_A$ 。通过改变 $QP_F$ ( 30~50, step 2 ) 来得到能最小化 $D$ 和 $D_A$ 的拉格朗日乘子 $\lambda$ 和 $\lambda_A$。 使用 $QP_F(\lambda)= a\cdot\ln(\lambda+b)+c$ 拟合,通过给定 $QP_F$ 计算最优拉格朗日乘子。
Feature-based Affine Motion Compensation
利用压缩特征描述符提高视频压缩率。本文通过利用特征描述符改善帧间运动估计精度。
使用压缩的特征描述符来建立仿射运动模型,这需要仿射参数构成的一个转换矩阵 $T$ 用于编码和解码。这些参数可以通过传输特征的特征匹配得到或者通过邻接块推导。
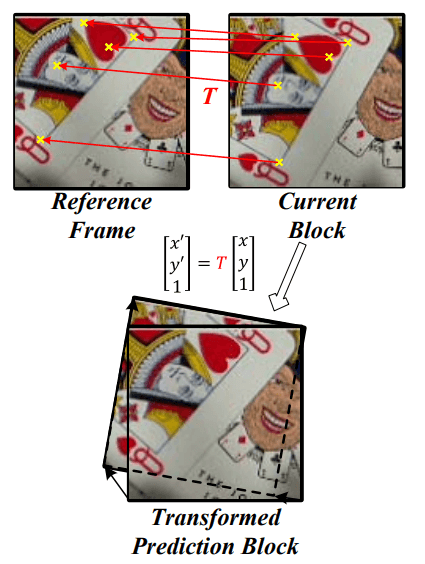
对于第一种方式,获得所有块的压缩特征,然后在参考帧和当前块上使用这些特征进行特征匹配。对于匹配特征对,使用 RANSAC 算法可以得到仿射转变矩阵 $T_0$ ,$T_0$ 通过梯度下降方法最小化当前块和参考像素之间的差异进行进一步优化,优化公式如下,$I$ 表示对应位置的像素
解码器可以得到仿射转变矩阵,所以只需要发送仿射转变矩阵差 $(T-T_0)$ 以减少比特
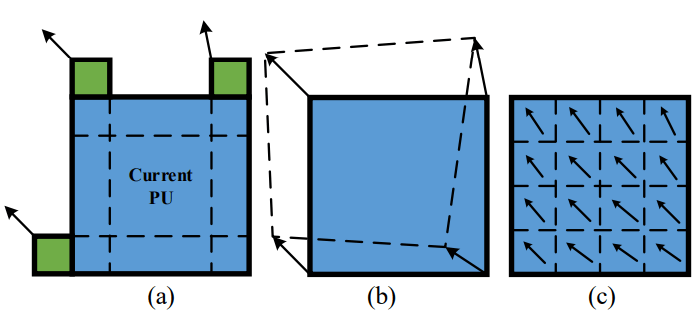
第二种方式,具有两种模式,the affine merge/skip mode 。使用三个角落的运动向量来计算当前块的仿射变化矩阵,如上图。
Experiment
在视频编码和特征编码的关系上,使用前一帧视频指导当前帧的特征编码,在使用特征编码指导当前帧的视频编码。
It is worth mentioning that there is no chicken-and-egg dilemma in the proposed joint compression scheme, since the feature coding is performed before video coding, and the information from previous video frames is used to guide the feature compression.
Evaluation of Feature Coding
数据集:MAR database 、RLD database
评估内容:压缩视频描述符的表现
三方面测量:Matching performance、Localization perform、Retrieval performance
首先测量 匹配描述符的数量 $N_{inliers}$ 来评估各个部分独立的有效性。
后验证分块指导的特征选择 (BP-FS) 在不同 $QP_F$ 下的效果,通常高的 $QP_F$ 能降低比特率的效果,也降低了检索表现。
再通过与 Baroffio 的方法 (一种ATC方法) 对比,结果显示本文方法的 $N_{inliers}$ 表现更好,这表示本文方法能更加紧凑的表示视频描述符,且达到更高的检索性能。
比较了与 ATC (Baroffio ) 和 CTA 的之间复杂度,虽然比 ATC 耗时多一点,但是比 CTA 改善很多。
Performance Evaluation of Video Coding
与 HEVC 测试模型 HM-14.0 对比,验证本文基于特征的仿射运动补偿的视频编码。
参数设置,$QP_F$ 设为 55,每帧的最大提取特征数量为 50,采用 HEVC 通用测试条件配置。
评估指标: BD-rate
结果:本文方法相对于 RA 配置下的 HEVC 达到了显著的比特率下降,且特征描述符的编码率在高比特率下可以忽略。对 HEVC 通用测试序列 Class-B 到 Class-D 进行评估,其改善效果不明显,因为这些数据集上一般没有仿射运动。