本文提出同时传输压缩图像和特征的方法,以提高图像视觉质量和面部识别任务的正确度。
- 同时压缩面部图像 (texture) 和深度特征
- 提出 TFQI 评估面部图像在自动化视觉分析和监控中的利用率
- 提出比特分配模式用于优化图像和特征的传输
本文以监控视频应用为例说明。
Framework
CTA : 压缩视频,然后传输到服务器分析图像。缺点带宽消耗大,服务器端重构图像会引入失真,降低特征质量。
ATC : 提取特征,压缩并传输特征,然后在服务器分析特征。优点带宽消耗小,缺点是丢失了图像纹理信息,缺少该特征将不能进行认为观察和监控。
所以本文联合压缩 图像纹理 和 原始图像特征,整体框架如下

首先对图像和序列使用面部识别算法如 MTCNN 检测面部,然后将检测到的面部图像进行大小缩放,用于深度学习特征提取和特征压缩。框架主要含三个模块,联合比特分配、纹理图像编码和深度特征编码。
纹理图像编码模块使用 HEVC/H.265 16 。
深度特征编码模块:深度特征由缩放后的面部图像提取,是深度网络中的最后一层的输出。提取的特征需要使用标量量化和熵编码。
标量量化使用 HEVC 的量化方法,其中量化步伐 $Q_{step}$ 由 QP 决定。由于不同 CNNs 中特征的元素取值范围不同,所以特征需要标准化,然后量化步伐可以进一步修改为
量化公式如下
$l$ 和 $c$ 分别为量化前后的特征相关系数,$floor$ 为截断操作。
最后对量化后的特征进行熵编码。服务端使用解码的特征进行高效面部识别任务,使用纹理图像进行人工监视。
TFQI-based Joint Bit Allocation
TFQI formulation
TFQI 指数用于衡量图像纹理和特征的质量。
其中 $w_1$ 和 $w_2$ 是权重系数,$D_1$ 和 $D_2$ 表示纹理失真和特征失真。$D_1$ 纹理失真使用 重构图像 和 原始图像之间的 MSE 表示,$D_2$ 使用面部识别的错误率表示。小程度的失真不容易被人眼或识别算法注意到,所以引入 $-\log$ 让小程度的失真更加显著。 $w_i$ 需要手动调整以均衡视觉质量和面部识别效果,以至于该指数可以用于不同应用。
Joint bit allocation
所占用的比特率直接会影响纹理图像和特征的质量。可以通过配置 QP 参数来配置所分配的比特率。对纹理图像和特征分配不同的比特率,以最大化应用表现(等价与最大化 TFQI ),即 对视频图像和特征的比特分配,目标是提高视觉质量和面部识别任务的正确度。
其中 $QP_1$ 和 $QP_2$ 分别为图像纹理和特征的量化参数,$R_t$ 和 $R_f$ 为二者对应使用的比特率。引入拉格朗日乘子解约束问题
故 $J$ 表示优化问题的目标函数,rate-TFQI cost 。对其求导求解
可得
其中 $w_i$ 为根据不同应用设置的参数,且
$D_i$ 与对应的$R_j$ 相关,通过不同比特率实验拟合二者的关系,得到
其中 $a_i$ 、 $b_i$ 、 $c_i$ 、 $d_i$ 与数据集有关的拟合参数。
整个优化过程为,实验拟合得到 $D_i$ 和对应 $R_j$ 的关系函数,再使用拉格朗日乘子解一个具有一个约束条件的函数极值问题
Experiment
数据集:LFW 18 ,使用 MTCNN 做捕捉面部图像,再缩放到 160 x 160 大小
对比方法:传统的 CTA 方法
对比指数:TFQI 指数( 涉及计算 $D_1$ 图像 MSE 和 $D_2$ 面部识别准确度 )和 rate-accuracy 表现
面部图像编码配置:HEVC 参考软件 HM-16.0 ,使用 All-Intra 配置;QP 取值有 22, 27, 32, 37, 42, 47, 51,对应比特率从小到大。
特征编码配置:使用 FaceNet 13 提取面部图像的特征,每个特征压缩为 128 维度的向量
在计算面部识别准确度时,使用了 6000 对图像进行面部识别,一半是相同人的图像对,一半是不同人的图像对。预测结果与 ground-truth 对比以衡量出准确度。
结果:
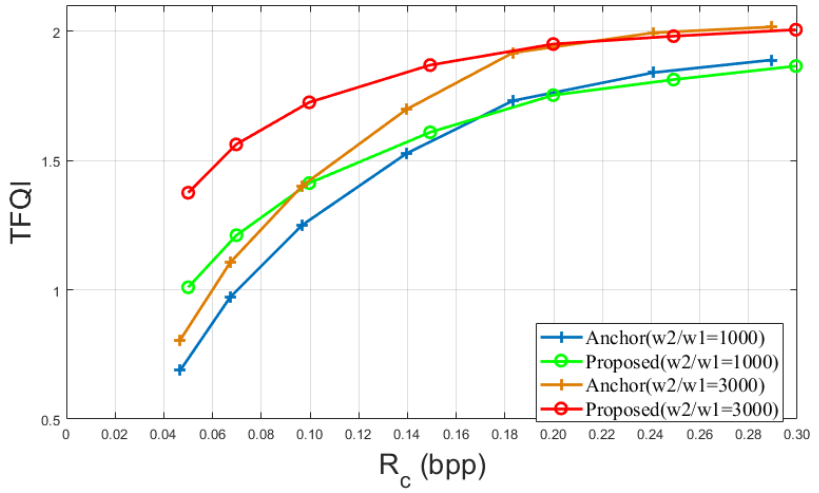
TFQI 对比,使用了不同的 $w_i$ 参数,结果显示本文方法的 TFQI 比 CTA 要好,尤其是在低比特率下的,且比特率越低,本文方法的改善越大,
对于纹理图像的视觉效果上,在相同比特率下本文方法的纹理图像比特率较 CTA 低(因为特征编码消耗了部分比特率),但是图像的视觉质量的差异却很小,尤其是在高比特率下。即达到了本文方法的最终目标:显著提升 CV 任务表现,且维护与 CTA 相似的视觉质量。
无论 $w_i$ 参数设置比例如何, CV 任务效果提升越大(为特征分配更多的比特率),必然导致图像视觉效果下降(纹理图像所分配的比特率变少),因为本文方法中二者相互”排斥”。在特定应用场景下 $D_i$ 和 $R_j$ 的关系是固定的,若 $w_2$ 取值变大,则比特率分配的优化方向会偏向为特征编码分配更多的比特率;反之亦然。
但是 A Joint Compression Scheme of Video Feature Descriptors and Visual Content 文中的方法,特征编码和视频编码有相互调节优化的处理(利用特征改善运动估计精度,提高视频压缩率,且特征提取方式更复杂,使用前一帧指导当前帧的特征选取 ),能够做到在引入特征编码提升 CV 任务效果的同时,提高视频的视觉质量。
( 两篇论文中有三位共同的作者,且本文属于发表于2018,而另一文发表于2016 = = )
在较低比特率下,本文方法确实是在较小的牺牲视觉质量的情况下,较大的提高了 CV 任务的效果。个人理解为,在比特率较低情况下,传输的图像质量过差,不足以让服务器的 CV 算法从中提取出足够的特征进行 CV 任务,而这个时候,若在客户端编码传输一定量的原始图像特征,便能显著改善服务器端 CV 算法的效果。故可以探究 CV 算法效果与输入特征的关系,发送最低限度的特征量以保证 CV 任务的效果。
Annotation
13. CVPR 2015 Open Access Repository ↩
16. Overview of the High Efficiency Video Coding (HEVC) standard ↩
18. Inria - Labeled Faces in the Wild: A Database forStudying Face Recognition in Unconstrained Environments ↩