本文为 Semantic image synthesis 任务提出了基于空间自适应的 normalization ,以更好地保存利用输入 segmentation mask 的信息。

project web: SPADE Project Page
Intro
Conditional image synthesis
指在给定条件下生成图像的任务。如给出语义分类图像,生成一张真实的图像;给一段描述文本,生成一张图像等。本文作者的应用是在给定语义分割掩码下,生成逼真的照片图像。
Normalization layers
规范化方式分为两种,即 Unconditional 和 Conditional 。
其中 Batch Normalization 、Instance Normalization 和 Layer Normalization 等为无条件的,因为其不需要额外的数据,直接对输入进行规范化(调整数据的均值、方差等)。
Conditional 方式有 Conditional BN 和 AdaIN , 它们先将数据调整为 0 均值和 1 方差,然后使用额外数据学到的仿射变化进一步调整数据。
Semantic Image Synthesis
使用 ${\textbf m} \in {\mathbb L} ^{H\times W}$ 表示语义分割掩码图,$\mathbb L$ 表示寓意类别数目,$H$ 和 $W$ 为掩码图的高宽。$\rm m$ 中的每个像素表示一个类别。本文任务是通过语义分割掩码 $\textbf m$ ,生成真实风格图像。
Spatially-adaptive denormalization (SPADE)
使用 $\textbf{h}^i$ 表示深度卷积网络中第 $i$ 层卷积激活后的特征图,$C^i$ 表示该层特征图的通道数,$H^i$ 和 $W^i$ 分别为该层特征图的高宽, $N$ 为 batch size。
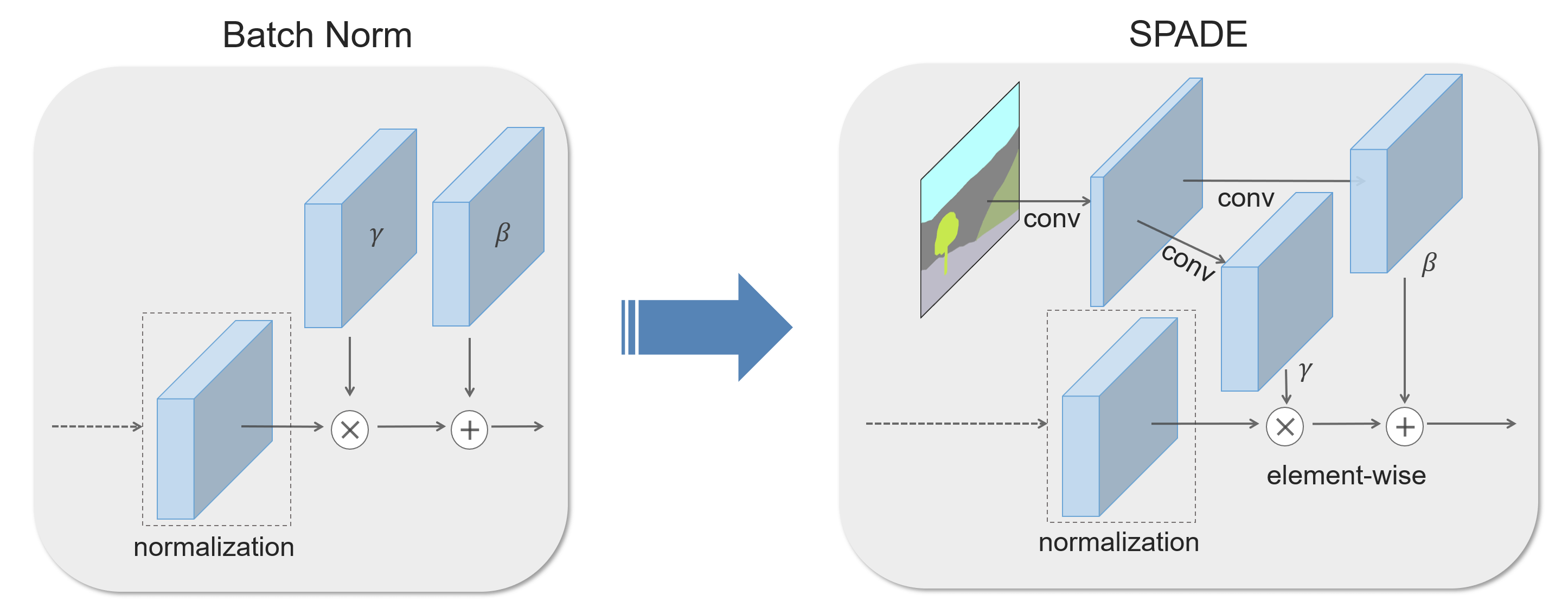
SPADE 规范化的数学表述为
其中 $\gamma^i_{c,y,x}$ 和 $\beta^i_{c,y,x}$ 表示将 $\textbf m$ 转换为对应位置 $(c,y,z)$ 的系数和偏置的函数,使用卷积方式实现。$\mu^i_c$ 和 $\sigma^i_c$ 为通道 $c$ 上数据的均值和方差。所以 PSADE 规范化即是先规范化数据的均值和反差 (normalization),在使用学习到的参数对数据进行一个变化 (denormalization)。
$\mu^i_c$ 和 $\sigma^i_c$ 是对通道上的数据计算的实数,而 $\gamma^i_{c,y,x}$ 和 $\beta^i_{c,y,x}$ 是对通道上数据卷积出来的一个相同大小 ($H\times W$) 的 tensor, 即对 $H\times W$ 空间上每个位置 ($x,y$) 都有一个对应的值,所以该
denormalization是spatially。
对于空间不变的条件数据(即 ${\textbf m}$ 是无变化的),SPADE 退化为 Conditional BN 。在特定情况下,也能退化为 AdaIN 。
作者认为 $\gamma$ 和 $beta$ 是由卷积提取的,能够自适应
segmentation mask,从而SPADE更适合语义图像合成任务。
SPADE generator
作者使用 SPADE 提取 segmentation mask 信息,故不再将其作为模型的输入,将生成器简化为一个 decoder ,输入为随机噪声。生成器由带有残差块组成,结构如下
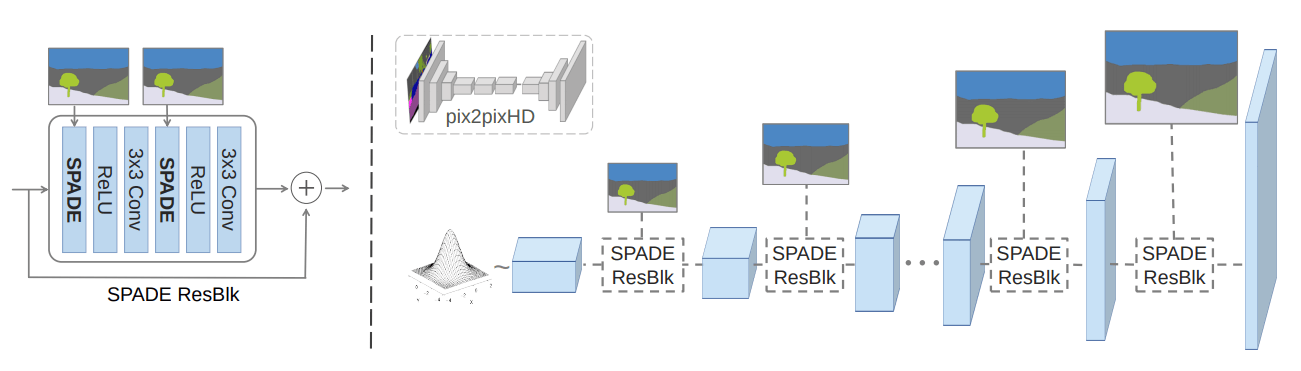
注意,不同深度的残差块的大小不一样,因此 SPADE 需要对 segmentation mask 进行下采样以适应空间大小。
作者使用 pix2pixHD 相同的判别器和 loss 来训练生成器,不同之处在于使用 hinge loss 替换了 最小二乘loss。
该模型的输入为随机噪声。若通过一个 encoder 来对某一目标图像进行编码得到噪声作为生成器的输入,可以生成带有目标图像风格的输出,因为该噪声分布具有目标图像的风格信息。效果如下

在同一个
segmentation mask下,使用不同的噪声,会生成不同的结果图。
Why does SPADE work better?
以一个简单的模型为例,该模型具有一个卷积层和一个规范化层,使用 segmentation mask 作为输入。当输入的 mask 只有一种标签,即像素值都是一样的时候。卷积出的值会被规范化层规范。这之后若再使用 InstanceNorm ,则规范化的值会变为 0 ,导致语义信息完全丢失。
而在 SPADE 中, mask 卷积后的值没有规范化操作,只有对前一层的特征进行规范化,能更好的保留语义信息。